Server-Sent Events: the alternative to WebSockets you should be using

When developing real-time web applications, WebSockets might be the first thing that come to your mind. However, Server Sent Events (SSE) are a simpler alternative that is often superior.
Contents
Prologue
Recently I have been curious about the best way to implement a real-time web application. That is, an application containing one ore more components which automatically update, in real-time, reacting to some external event. The most common example of such an application, would be a messaging service, where we want every message to be immediately broadcasted to everyone that is connected, without requiring any user interaction.
After some research I stumbled upon an amazing talk by Martin Chaov, which compares Server Sent Events, WebSockets and Long Polling. The talk, which is also available as a blog post, is entertaining and very informative. I really recommend it. However, it is from 2018 and some small things have changed, so I decided to write this article.
WebSockets?
WebSockets enable the creation of two-way low-latency communication channels between the browser and a server.
This makes them ideal in certain scenarios, like multiplayer games, where the communication is two-way, in the sense that both the browser and server send messages on the channel all the time, and it is required that these messages be delivered with low latency.
In a First-Person Shooter, the browser could be continuously streaming the player’s position, while simoultaneously receiving updates on the location of all the other players from the server. Moreover, we definitely want these messages to be delivered with as little overhead as possible, to avoid the game feeling sluggish.
This is the opposite of the traditional request-response model of HTTP, where the browser is always the one initiating the communication, and each message has a significant overhead, due to establishing TCP connections and HTTP headers.
However, many applications do not have requirements this strict. Even among real-time applications, the data flow is usually asymmetric: the server sends the majority of the messages while the client mostly just listens and only once in a while sends some updates. For example, in a chat application an user may be connected to many rooms each with tens or hundreds of participants. Thus, the volume of messages received far exceeds the one of messages sent.
What is wrong with WebSockets
Two-way channels and low latency are extremely good features. Why bother looking further?
WebSockets have one major drawback: they do not work on top of HTTP, at least not fully. They require their own TCP connection. They use HTTP only to establish the connection, but then upgrade it to a standalone TCP connection on top of which the WebSocket protocol can be used.
This may not seem a big deal, however it means that WebSockets cannot benefit from any HTTP feature. That is:
- No support for compression
- No support for HTTP/2 multiplexing
- Potential issues with proxies
- No protection from Cross-Site Hijacking
At least, this was the situation when the WebSocket protocol was first released. Nowadays, there are some complementary standards that try to improve upon this situation. Let’s take a closer look to the current situation.
Note: If you do not care about the details, feel free to skip the rest of this section and jump directly to Server-Sent Events or the demo.
Compression
On standard connections, HTTP compression is supported by every browser, and is super easy to enable server-side. Just flip a switch in your reverse-proxy of choice. With WebSockets the question is more complex, because there are no requests and responses, but one needs to compress the individual WebSocket frames.
RFC 7692, released on December 2015, tries to improve the situation by definining “Compression Extensions for WebSocket”. However, to the best of my knowledge, no popular reverse-proxy (e.g. nginx, caddy) implements this, making it impossible to have compression enabled transparently.
This means that if you want compression, it has to be implemented directly in your backend. Luckily, I was able to find some libraries supporting RFC 7692. For example, the websockets and wsproto Python libraries, and the ws library for nodejs.
However, the latter suggests not to use the feature:
The extension is disabled by default on the server and enabled by default on the client. It adds a significant overhead in terms of performance and memory consumption so we suggest to enable it only if it is really needed.
Note that Node.js has a variety of issues with high-performance compression, where increased concurrency, especially on Linux, can lead to catastrophic memory fragmentation and slow performance.
On the browsers side, Firefox supports WebSocket compression since version 37. Chrome supports it as well. However, apparently Safari and Edge do not.
I did not take the time to verify what is the situation on the mobile landscape.
Multiplexing
HTTP/2 introduced support for multiplexing, meaning that multiple request/response pairs to the same host no longer require separate TCP connections. Instead, they all share the same TCP connection, each operating on its own independent HTTP/2 stream.
This is, again, supported by every browser and is very easy to transparently enable on most reverse-proxies.
On the contrary, the WebSocket protocol has no support, by default, for multiplexing. Multiple WebSockets to the same host will each open their own separate TCP connection. If you want to have two separate WebSocket endpoints share their underlying connection you must add multiplexing in your application’s code.
RFC 8441, released on September 2018, tries to fix this limitation by adding support for “Bootstrapping WebSockets with HTTP/2”. It has been implemented in Firefox and Chrome. However, as far as I know, no major reverse-proxy implements it. Unfortunately, I could not find any implementation in Python or Javascript either.
Issues with proxies
HTTP proxies without explicit support for WebSockets can prevent unencrypted WebSocket connections to work. This is because the proxy will not be able to parse the WebSocket frames and close the connection.
However, WebSocket connections happening over HTTPS should be unaffected by this problem, since the frames will be encrypted and the proxy should just forward everything without closing the connection.
To learn more, see “How HTML5 Web Sockets Interact With Proxy Servers” by Peter Lubbers.
Cross-Site WebSocket Hijacking
WebSocket connections are not protected by the same-origin policy. This makes them vulnerable to Cross-Site WebSocket Hijacking.
Therefore, WebSocket backends must check the correctness of the Origin header,
if they use any kind of client-cached authentication, such as cookies or
HTTP authentication.
I will not go into the details here, but consider this short example. Assume
a Bitcoin Exchange uses WebSockets to provide its trading service. When you
log in, the Exchange might set a cookie to keep your session active
for a given period of time. Now, all an attacker has to do to steal your precious
Bitcoins is make you visit a site under her control, and simply open a WebSocket
connection to the Exchange. The malicious connection is going to be automatically
authenticated. That is, unless the Exchange checks the Origin header and blocks
the connections coming from unauthorized domains.
I encourage you to check out the great article about Cross-Site WebSocket Hijacking by Christian Schneider, to learn more.
Server-Sent Events
Now that we know a bit more about WebSockets, including their advantages and shortcomings, let us learn about Server-Sent Events and find out if they are a valid alternative.
Server-Sent Events enable the server to send low-latency push events to the client, at any time. They use a very simple protocol that is part of the HTML Standard and supported by every browser.
Unlike WebSockets, Server-sent Events flow only one way: from the server to the client. This makes them unsuitable for a very specific set of applications, that is, those that require a communication channel that is both two-way and low latency, like real-time games. However, this trade-off is also their major advantage over WebSockets, because being one-way, Server-Sent Events work seamlessly on top of HTTP, without requiring a custom protocol. This gives them automatic access to all of HTTP’s features, such as compression or HTTP/2 multiplexing, making them a very convenient choice for the majority of real-time applications, where the bulk of the data is sent from the server, and where a little overhead in requests, due to HTTP headers, is acceptable.
The protocol is very simple. It uses the text/event-stream Content-Type and
messages of the form:
data: First message
event: join
data: Second message. It has two
data: lines, a custom event type and an id.
id: 5
: comment. Can be used as keep-alive
data: Third message. I do not have more data.
data: Please retry later.
retry: 10Each event is separated by two empty lines (\n) and consists of various optional
fields.
The data field, which can be repeted to denote multiple lines in the message,
is unsurprisingly used for the content of the event.
The event field allows to specify custom event types, which as we will show
in the next section, can be used to fire different event handlers on the client.
The other two fields, id and retry, are used to configure the behaviour of the automatic
reconnection mechanism. This is one of the most interesting features of Server-Sent
Events. It ensures that
when the connection is dropped or closed by the server, the client will
automatically try to reconnect, without any user intervention.
The retry field is used to specify the minimum amount of time, in seconds,
to wait before trying to reconnect.
It can also be sent by a server, immediately before closing the client’s connection,
to reduce its load when too many clients are connected.
The id field associates an identifier with the current event. When reconnecting
the client will transmit to the server the last seen id, using the Last-Event-ID HTTP header.
This allows the stream to be resumed from the correct point.
Finally, the server can stop the automatic reconnection mechanism altogether by returning an HTTP 204 No Content response.
Let’s write some code!
Let us now put into practice what we learned. In this section we will implement a simple service both with Server-Sent Events and WebSockets. This should enable us to compare the two technologies. We will find out how easy it is to get started with each one, and verify by hand the features discussed in the previous sections.
We are going to use Python for the backend, Caddy as a reverse-proxy and of course a couple of lines of JavaScript for the frontend.
To make our example as simple as possible, our backend is just going to consist of
two endpoints, each streaming a unique sequence of random numbers. They are going to be reachable from
/sse1 and /sse2 for Server-Sent Events, and from /ws1 and /ws2 for
WebSockets. While our frontend is going to consist of a single index.html
file, with some JavaScript which will let us start and stop WebSockets and
Server-Sent Events connections.
The code of this example is available on GitHub.
The Reverse-Proxy
Using a reverse-proxy, such as Caddy or nginx, is very useful, even in a small example such as this one. It gives us very easy access to many features that our backend of choice may lack.
More specifically, it allows us to easily serve static files and automatically compress HTTP responses; to provide support for HTTP/2, letting us benefit from multiplexing, even if our backend only supports HTTP/1; and finally to do load balancing.
I chose Caddy because it automatically manages for us HTTPS certificates, letting us skip a very boring task, especially for a quick experiment.
The basic configuration, which resides in a Caddyfile at the root of our
project, looks something like this:
localhost
bind 127.0.0.1 ::1
root ./static
file_server browse
encode zstd gzipThis instructs Caddy to listen on the local interface on ports 80 and 443,
enabling support for HTTPS and generating a self-signed certificate. It also
enables compression and serving static files from the static directory.
As the last step we need to ask Caddy to proxy our backend services. Server-Sent Events is just regular HTTP, so nothing special here:
reverse_proxy /sse1 127.0.1.1:6001
reverse_proxy /sse2 127.0.1.1:6002To proxy WebSockets our reverse-proxy needs to have explicit support for it. Luckily, Caddy can handle this without problems, even though the configuration is slighly more verbose:
@websockets {
header Connection *Upgrade*
header Upgrade websocket
}
handle /ws1 {
reverse_proxy @websockets 127.0.1.1:6001
}
handle /ws2 {
reverse_proxy @websockets 127.0.1.1:6002
}Finally you should start Caddy with
$ sudo caddy startThe Frontend
Let us start with the frontend, by comparing the JavaScript APIs of WebSockets and Server-Sent Events.
The WebSocket JavaScript API is very simple to use.
First, we need to create a new
WebSocket object passing the URL of the server. Here wss indicates that
the connection is to happen over HTTPS. As mentioned above it is really recommended
to use HTTPS to avoid issues with proxies.
Then, we should listen to some of the possible events (i.e. open,
message, close, error), by either setting the on$event property or
by using addEventListener().
const ws = new WebSocket("wss://localhost/ws");
ws.onopen = e => console.log("WebSocket open");
ws.addEventListener(
"message", e => console.log(e.data));The JavaScript API for Server-Sent Events is very similar. It requires us to
create a new EventSource object passing the URL of the server, and then
allows us to subscribe to the events in the same way as before.
The main difference is that we can also subscribe to custom events.
const es = new EventSource("https://localhost/sse");
es.onopen = e => console.log("EventSource open");
es.addEventListener(
"message", e => console.log(e.data));
// Event listener for custom event
es.addEventListener(
"join", e => console.log(`${e.data} joined`))We can now use all this freshly aquired knowledge about JS APIs to build our actual frontend.
To keep things as simple as possible, it is going to consist of only one index.html
file, with a bunch of buttons that will let us start and stop our WebSockets
and EventSources. Like so
<button onclick="startWS(1)">Start WS1</button>
<button onclick="closeWS(1)">Close WS1</button>
<br>
<button onclick="startWS(2)">Start WS2</button>
<button onclick="closeWS(2)">Close WS2</button>We want more than one WebSocket/EventSource so we can test if HTTP/2 multiplexing works and how many connections are open.
Now let us implement the two functions needed by those buttons to work:
const wss = [];
function startWS(i) {
if (wss[i] !== undefined) return;
const ws = wss[i] = new WebSocket("wss://localhost/ws"+i);
ws.onopen = e => console.log("WS open");
ws.onmessage = e => console.log(e.data);
ws.onclose = e => closeWS(i);
}
function closeWS(i) {
if (wss[i] !== undefined) {
console.log("Closing websocket");
websockets[i].close();
delete websockets[i];
}
}The frontend code for Server-Sent Events is almost identical. The only difference
is the onerror event handler, which is there because in case of error a message
is logged and the browser will attempt to reconnect.
const ess = [];
function startES(i) {
if (ess[i] !== undefined) return;
const es = ess[i] = new EventSource("https://localhost/sse"+i);
es.onopen = e => console.log("ES open");
es.onerror = e => console.log("ES error", e);
es.onmessage = e => console.log(e.data);
}
function closeES(i) {
if (ess[i] !== undefined) {
console.log("Closing EventSource");
ess[i].close()
delete ess[i]
}
}The Backend
To write our backend, we are going to use Starlette, a simple async web framework for Python, and Uvicorn as the server. Moreover, to make things modular, we are going to separate the data-generating process, from the implementation of the endpoints.
We want each of the two endpoints to generate an unique random sequence
of numbers. To accomplish this we will use the stream id (i.e. 1 or 2) as
part of the random seed.
Ideally, we would also like our streams to be resumable. That is, a client
should be able to resume the stream from the last message it received, in case
the connection is dropped, instead or re-reading the whole sequence.
To make this possible we will assign an ID to each message/event, and use it
to initialize the random seed, together with the stream id, before each message
is generated.
In our case, the ID is just going to be a counter starting from 0.
With all that said, we are ready to write the get_data function which is
responsible to generate our random numbers:
import random
def get_data(stream_id: int, event_id: int) -> int:
rnd = random.Random()
rnd.seed(stream_id * event_id)
return rnd.randrange(1000)Let’s now write the actual endpoints.
Getting started with Starlette is very simple. We just need to initialize
an app and then register some routes:
from starlette.applications import Starlette
app = Starlette()To write a WebSocket service both our web server and framework of choice must have explicit support. Luckily Uvicorn and Starlette are up to the task, and writing a WebSocket endpoint is as convenient as writing a normal route.
This all the code that we need:
from websockets.exceptions import WebSocketException
@app.websocket_route("/ws{id:int}")
async def websocket_endpoint(ws):
id = ws.path_params["id"]
try:
await ws.accept()
for i in itertools.count():
data = {"id": i, "msg": get_data(id, i)}
await ws.send_json(data)
await asyncio.sleep(1)
except WebSocketException:
print("client disconnected")The code above will make sure our websocket_endpoint function is called every time
a browser requests a path starting with /ws and followed by a number (e.g. /ws1, /ws2).
Then, for every matching request, it will wait for a WebSocket connection to be established and subsequently start an infinite loop sending random numbers, encoded as a JSON payload, every second.
For Server-Sent Events the code is very similar, except that no special
framework support is needed.
In this case, we register a route matching URLs starting with /sse and ending
with a number (e.g. /sse1, /sse2).
However, this time our endpoint just sets the appropriate headers and returns a StreamingResponse:
from starlette.responses import StreamingResponse
@app.route("/sse{id:int}")
async def sse_endpoint(req):
return StreamingResponse(
sse_generator(req),
headers={
"Content-type": "text/event-stream",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
},
)StreamingResponse is an utility class, provided by Starlette, which takes a generator and streams
its output to the client, keeping the connection open.
The code of sse_generator is shown below, and is almost identical to the WebSocket
endpoint, except that messages are encoded according to the Server-Sent Events
protocol:
async def sse_generator(req):
id = req.path_params["id"]
for i in itertools.count():
data = get_data(id, i)
data = b"id: %d\ndata: %d\n\n" % (i, data)
yield data
await asyncio.sleep(1)We are done!
Finally, assuming we put all our code in a file named server.py, we can start
our backend endpoints using Uvicorn, like so:
$ uvicorn --host 127.0.1.1 --port 6001 server:app &
$ uvicorn --host 127.0.1.1 --port 6002 server:app &Bonus: Cool SSE features
Ok, let us now conclude by showing how easy it is to implement all those nice features we bragged about earlier.
Compression can be enabled by changing just a few lines in our endpoint:
@@ -32,10 +33,12 @@ async def websocket_endpoint(ws):
async def sse_generator(req):
id = req.path_params["id"]
+ stream = zlib.compressobj()
for i in itertools.count():
data = get_data(id, i)
data = b"id: %d\ndata: %d\n\n" % (i, data)
- yield data
+ yield stream.compress(data)
+ yield stream.flush(zlib.Z_SYNC_FLUSH)
await asyncio.sleep(1)
@@ -47,5 +50,6 @@ async def sse_endpoint(req):
"Content-type": "text/event-stream",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
+ "Content-Encoding": "deflate",
},
)We can then verify that everything is working as expected by checking the DevTools:
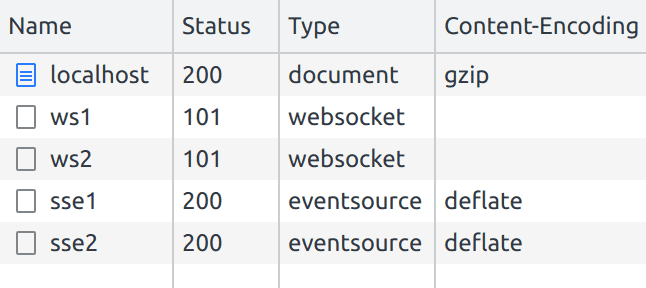
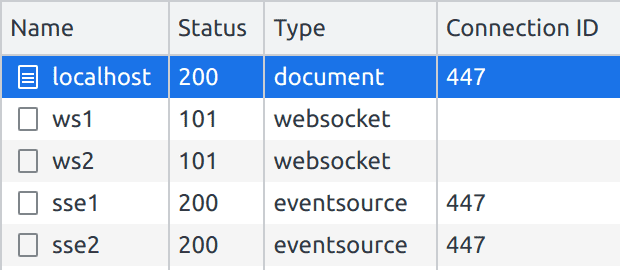
Multiplexing is enabled by default since Caddy supports HTTP/2. We can confirm that the same connection is being used for all our SSE requests using the DevTools again:
Automatic reconnection on unexpected connection errors is as simple as
reading the Last-Event-ID header in our backend code:
< for i in itertools.count():
---
> start = int(req.headers.get("last-event-id", 0))
> for i in itertools.count(start):Nothing has to be changed in the front-end code.
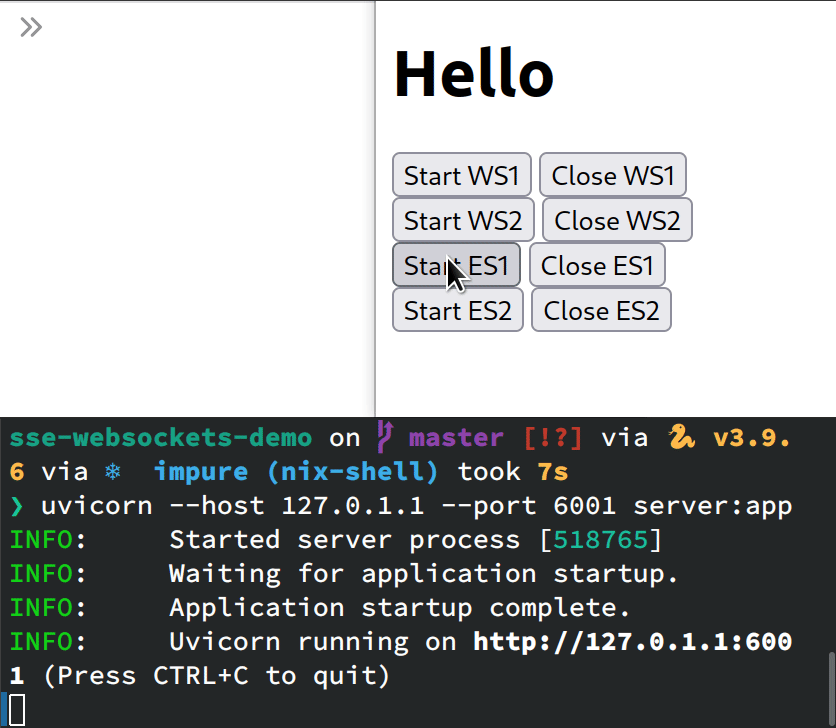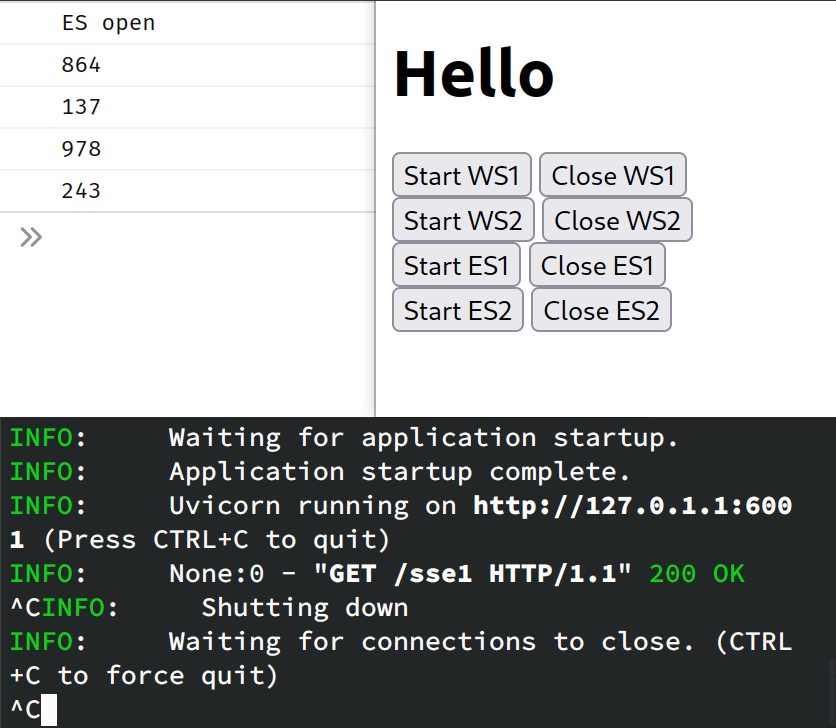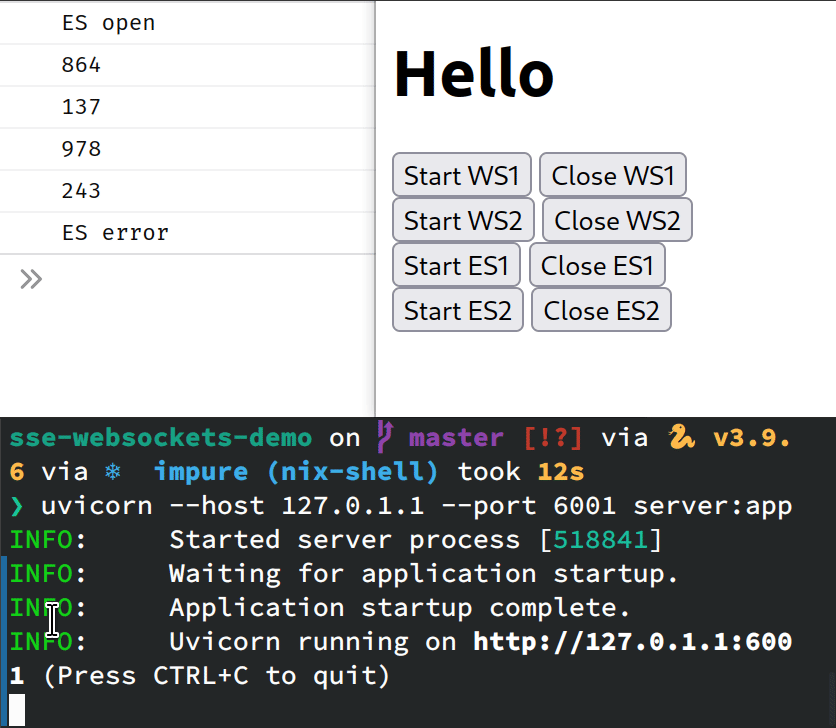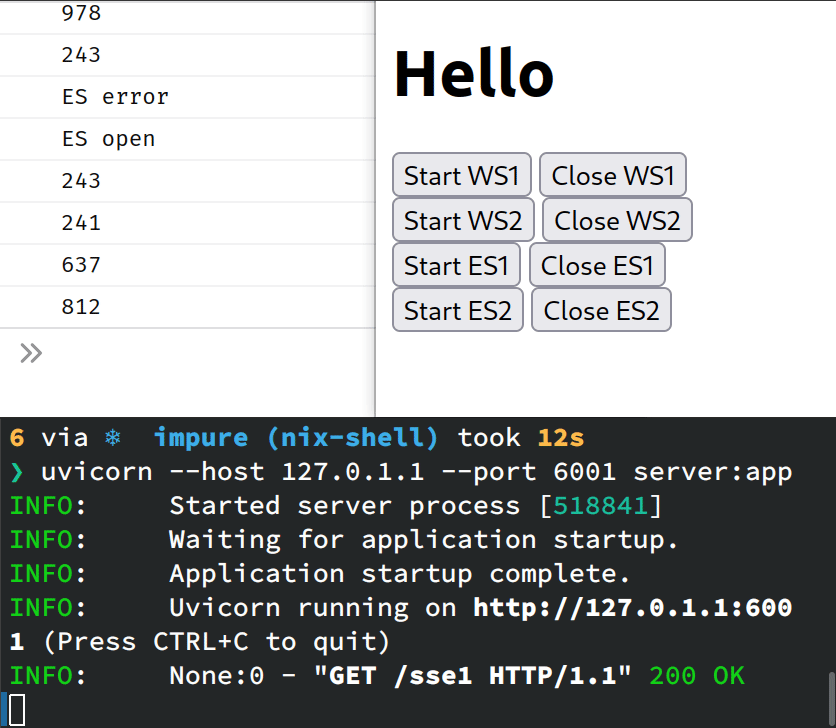
We can test that it is working by starting the connection to one of the SSE endpoints and then killing uvicorn. The connection will drop, but the browser will automatically try to reconnect. Thus, if we re-start the server, we will see the stream resume from where it left off!
Notice how the stream resumes from the message 243. Feels like magic 🔥
Conclusion
WebSockets are a big machinery built on top of HTTP and TCP to provide a set of extremely specific features, that is two-way and low latency communication.
In order to do that they introduce a number of complications, which end up making both client and server implementations more complicated than solutions based entirely on HTTP.
These complications and limitations have been addressed by new specs (RFC 7692, RFC 8441), and will slowly end up implemented in client and server libraries.
However, even in a world where WebSockets have no technical downsides, they will still be a fairly complex technology, involving a large amount of additional code both on clients and servers. Therefore, you should carefully consider if the addeded complexity is worth it, or if you can solve your problem with a much simpler solution, such as Server-Sent Events.
That’s all, folks! I hope you found this post interesting and maybe learned something new.
Feel free to check out the code of the demo on GitHub, if you want to experiment a bit with Server Sent Events and Websockets.
I also encourage you to read the spec, because it surprisingly clear and contains many examples.

Comments
https://store.steampowered.com/app/486310/Meadow/
We have had a total of 350.000 players over 6 years and the backend out-scales all other multiplayer servers that exist and it's open source:
https://github.com/tinspin/fuse
You don't need HTTP/2 to make SSE work well. Actually the HTTP/2 TCP head-of-line issue and all the workarounds for that probably make it harder to scale without technical debt.
Can you explain what you mean here? What was your peak active user count, what was peak per server instance, and why you think that beats anything else?
Under Performance. Per watt the fuse/rupy platform completely crushes all competition for real-time action MMOs because of 2 reasons:
- Event driven protocol design, averages at about 4 messages/player/second (means you cannot do spraying or headshots f.ex. which is another feature in my game design opinion).
- Java's memory model with atomic concurrency parallelism over shared memory which needs a VM and GC to work (C++ copied that memory model in C++11, but it failed completely because they lack both VM and GC, but that model is still to this day the one C++ uses), you can read more about this here: https://github.com/tinspin/rupy/wiki
These keep the internal latency of the server below maybe 100 microseconds at saturation, which no C++ server can handle even remotely, unless they copy Java's memory model and add a VM + GC so that all cores can work on the same memory at the same time without locking!
You can argue those points are bad arguments, but if you look at performance per watt with some consideration for developer friendlyness, I'm pretty sure in 100 years we will still be coding minimalist JavaSE (or some copy without Oracle) on the server and vanilla C (compiled with C++ compiler gcc/cl.exe) on the client to avoid cache misses.
Energy is everything!
Do you have a link that explains this bit?
I don't understand what particular piece of magic makes shared-memory concurrency under a VM+GC faster than a CAS implementation.
[1] I'm assuming a shared-memory threaded model of concurrency, not a shared-nothing message passing model of concurrency.
Me neither, but I know it does in practice.
My intuition tells me the VM provides a layer decoupled from the hardware memory model so that there is less "friction" and the GC is required to reclaim shared memory that C++ would need to "stop the world" to reclaim anyhow! (all concurrent C++ objects leaks memory, see TBB concurrent_hash_map f.ex.) That means the code executes slower BUT the atomics can work better.
As I said; for 5 years I have been searching for answers from EVERYONE on the planet and nobody can answer. My guess is that this is so complicated, only a handfull can even begin to grook it, so nobody wants to explain it because it creates alot of wasted time.
The usual reaction is: Java is written in C, so how can Java be faster than C? Well I don't know how but I know it's true because I use it!
So my answer today is: Java is faster than C if you want to share memory between threads directly efficiently because you need a VM with GC to make the Java memory model (which everyone has copied so I guess it must be good?) work!
Here is someone who knows his concurrency and made C++ maps that might be better than TBB btw: https://github.com/preshing/junction
But no guarantees... you never get those with C/C++, I stopped downloading C/C++ code from the internet unless it has 100+ proved users! So stb/ttf and kuba/zip are my only dependencies.
https://en.wikipedia.org/wiki/Compare-and-swap
> My intuition tells me the VM provides a layer decoupled from the hardware memory model so that there is less "friction" and the GC is required to reclaim shared memory that C++ would need to "stop the world" to reclaim anyhow! (all concurrent C++ objects leaks memory, see TBB concurrent_hash_map f.ex.) That means the code executes slower BUT the atomics can work better.
I dunno about the GC bits; after all object pools are a thing in C++ so you have a consistent place (getting a new object) where reclamation of unused objects can be performed.
I think it might be down to mutex locking. In a native program, a failure to acquire the mutex causes a context-switch by performing a syscall (OS steps in, flushes registers, cache, everything, and runs some other thread).
In a VM language I would expect that a failure to acquire a mutex can be profiled by the VM with simple heuristics (Only one thread waiting for a mutex? Spin on the mutex until its released. More than five threads in the wait queue? Run some other thread).
That's said, it's very cool. Do you have a development blog for Meadow?
No, no dev log but I'll tell you some things that where incredible during that project:
- I started the fuse project 4 months before I set foot in the Meadow project office (we had like 3 meetings during those 4 months just to touch base on the vision)! This is a VERY good way of making things smooth, you need to give tech/backend/foundation people a head start of atleast 6 months in ANY project.
- We spent ONLY 6 weeks (!!!) implementing the entire games multiplayer features because I was 100% ready for the job after 4 months. Not a single hickup...
- Then for 7 months they finished the game client without me and released without ANY problems (I came back to the office that week and that's when I solved the anti-virus/proxy cacheing/buffering problem!).
I think Meadow is the only MMO in history so far to have ZERO breaking bugs on release (we just had one UTF-8 client bug that we patched after 15 minutes and nobody noticed except the poor person that put a strange character in their name).
Not MIT then. The beauty of MIT is that there is no stuff.
Here it's clear, you can either use the code without money involved and then you have MIT (+ show logo and some example code is still mine).
If you want money then you have to share some of it.
Your license is not that. You have extra conditions that add complexity. I can no longer go "oh like MIT" and immediately use it for any purpose, because you require extras especially if I were to make money. That seems completely against the spirit of the simplicity of the MIT license which says you can do whatever you like, commercial or otherwise, as long as the copyright and license are included.
I think you should make your own license that includes the text of the MIT license, except removing the irrelevant parts (ie the commercial aspects include a caveat about requiring payment). You can still have a separate line of text explaining that the license is like the MIT license but with XYZ changes (basically the text you have now). But the license is not the MIT license and you should therefore have a separate license text that spells it out exactly. Not "its this, except scratch half of it because these additional terms override a good chunk of it".
I'm also sad that nobody has solved this license problem yet, there is obviously a need for it. Sometimes time solves all problems though, so I probably just have to wait a while and somebody makes exactly the right license.
But I'm going to allocate some time if somebody who is willing to pay approaches me with the same concerns (it's actually why I switched to MIT in the first place, Unreal does not allow you to use client plugins that are LGPL)...
Small steps, we'll get there!
What? To keep your existing license you copy the text of the MIT license, add the statement about requiring a logo and remove the parts about being able to use the code commercially, and add an extra paragraph that has the text you already have: to use commercially you have to sponsor. It’s not about changing your terms, it’s about being clear about what license applies. Hybrid with MIT and other implies that the MIT license somehow applies yet it does not since your “other” invalidates a chunk of what the MIT license allows. Just removing those bits and not calling it MIT is enough.
If that significantly cuts into your time to do other stuff then I don’t know what to say.
> if somebody who is willing to pay approaches me with the same concerns
I’m not concerned about the license per se. It wouldn’t stop me from paying if I wanted to use your software. It’s just that to everyone looking, before even evaluating it, you’re sending a dishonest message, that somehow the MIT license applies when it clearly does not.
I would create a license.txt file that contains a copy of the MIT license text with the commercial use phrasing removed, the need for displaying logo added a second paragraph before the warranty disclaimer stating that you may use the software commercially so long as you sponsor (same text you already have). Then I would link it from the readme with an explanation: proprietary license that is similar to the MIT license except with the conditions of logo and for commercial use requiring sponsorship (existing text more or less). Clear, simple and should take you no more than ten minutes to fix.
My objection is that you are claiming it’s under MIT license and using the MIT licenses name recognition, while applying changes that very clearly make it not MIT license at all.
"Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:"
Became
"Permission is hereby granted, to any person obtaining a copy of this software and associated documentation files (the "Software"), to use the Software, including the rights to copy, modify, merge, publish and/or distribute the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:"
And then I list the stuff...
1) You have to show the logo on startup.
2) You have to sponsor the fuse tier on gumroad while you are using the Software, or any derived Software, commercially:
https://tinspin.gumroad.com/l/xwluh
3) The .html and graphics are proprietary examples except the javascript in play.html
4) The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
it feels completely meaningless to put it that way... laws are really the most superficial waste of time, it only took 5 minutes to edit but it's a lifetime of trouble!
But thanks I guess, if it works... but you only know that later... possibly eons later!
> I didn't know how small the MIT license was!!!
This is kind of a problem, before you were saying its like the MIT license but if you didn't know how small it was, you couldn't have read it, so...
Anyway, no point in beating a dead horse, you have corrected the issue I had, so thank you!
> laws are really the most superficial waste of time
Until you need them, at least.
In any case, good luck with your project. It does technically look very interesting.
But really open-source (as in free) is the misnomer here, it should be called free open-source, or FOSS as some correctly name it.
The bare reality is that it's just a commercial license.
FOSS or F/OSS is a combination of Free (as defined by the FSF) and Open Source (as defined by the OSI) (the last S is Software), which recognizes that the two terms, while they come from groups with different ideological motivations, refer to approximately the same substantive licensing features and almost without exception the same set of licenses.
Since when was "open source" generic? These obnoxious idealists you're complaining about are the people who invented the term in the first place.
We all need to get out of the current legal/monetary system soon enough.
That said if you, like SSE on HTTP/1.1; use 2 sockets per client (breaking the RFC, one for upstream and one for downstream) you are golden but then why use HTTP/2 in the first place?
HTTP/2 creates more problems than solutions and so does HTTP/3 unfortunately until their protocol fossilizes which is the real feature of a protocol, to become stable so everyone can rely on things working.
In that sense HTTP/1.1 is THE protocol of human civilization until the end of times; together with SMTP (the oldest protocol of the bunch) and DNS (which is centralized and should be replaced btw).
Really people should try and build great things on the protocols we have instead of always trying to re-discover the wheel, note: NOT the same as re-inventing the wheel: http://move.rupy.se/file/wheel.jpg
It's amazing that we've been able to adapt the protocol in a backwards-compatible fashion for over 30 years, but QUIC addresses problems with TCP in ways that could not be done in a backwards-compatible fashion. Personally I wish the protocol were simpler, but I lack the expertise to say what should be removed.
Take Snap. Say they reduced time to view a snap by 10ms. After 100 snaps that’s an additional 1 second of engagement. This could equate to an additional ad impression every week per user. Which is many millions of additional revenue.
Please elaborate.
"QUIC is a new always-encrypted general-purpose transport protocol being standardized at the IETF designed for multiplexing multiple streams of data on a single connection. HTTP/3 runs over QUIC and roughly replaces HTTP/2 over TLS and TCP. QUIC combines the cryptographic and transport handshakes in a way to allow connecting to a new server in a single round trip and to allow establishing a resumed connection in zero round trips, with the client sending encrypted application data in its first flight. QUIC uses TLS 1.3 as the basis for its cryptographic handshake.
This talk will provide an overview of what the QUIC protocol does and how it works, and then will dive deep into some of the technical details. The deep dive will focus on security-related aspects of the protocol, including how QUIC combines the transport and cryptographic handshakes, and how resumption, including zero-round-trip resumption works. This will also cover how QUIC’s notion of a connection differs from the 5-tuple sometimes used to identify connections, and what QUIC looks like on the wire.
In addition to covering details of how QUIC works, this talk will also address implementation and deployment considerations. This will include how a load balancer can be used with cooperating servers to route connections to a fleet of servers while still maintaining necessary privacy and security properties. It will also look back at some of the issues with HTTP/2 and discuss which ones may need to be addressed in QUIC implementations as well or are solved by the design of QUIC and HTTP/3."
But even if the definition were different, http+tls would also be e2e encrypted (if used in conjunction which it pretty much always is).
I appreciate Quic but from a security perspective I don't see how it's different to what we've had for at least a decade.
So much nonsense in a single paragraph, amazing.
If anything DNS is less centralized then http and SMTP. Its a surprisingly complicated system for what it does because of all the caching etc, but calling it more centralized then http is just is just ignorant to a silly degree
My license is messy but if you search for "license" on the main github page you'll eventually find MIT + some ugly modifications I made.
https://github.com/open-wa/wa-automate-nodejs
There should be some sort of support group for those of us trying to monetize (sans donations) our open source projects!
We probably need a new license though because piggybacking on MIT (or any other license) like I try to do is rubbing people the wrong way.
But law and money are my least favourite passtimes, so I'm going to let somebody else do it first unless somebody is willing to force this change by buying a license and asking for a better license text.
Your source-available projects. Nothing wrong with licensing your work that way (in the sense that you can make that choice, not in the sense that I think its a good idea) but please don't muddle the term "open source".
1. https://jmap.io/spec-core.html#event-source
You can't say that and not say more about it, haha. Please expand on this?
Also, I'm a Fastmail customer and appreciate the nimble UI, thanks!
Before that... yeah, the Firefox dev tools were not very helpful for SSE.
It's a beautifully simple & elegant lightweight push events option that works over standard HTTP, the main gotcha for maintaining long-lived connections is that server/clients should implement their own heartbeat to be able to detect & auto reconnect failed connections which was the only reliable way we've found to detect & resolve broken connections.
That sounds like a total nightmare!
Also ease of use doesn’t really convince me. It’s like 5 lines of code with socket.io to have working websockets, without all the downsides of sse.
Server-sent events appears to me to just be chunked transfer encoding [0], with the data structured in a particular way (at least from the perspective of the server) in this reference implementation (tl,dr it's a stream):
https://gist.github.com/jareware/aae9748a1873ef8a91e5#file-s...
[0]: https://en.wikipedia.org/wiki/Chunked_transfer_encoding
Which seems to be what you need to send 'headers' after a chunked response.
You can kludge it with fetch(...) and the body stream
1. <https://developer.mozilla.org/en-US/docs/Web/API/EventSource>
With current day APIs, including streaming response bodies in the fetch API, SSE would probably not have been standardized as a separate browser API.
It's just random that your ISP like WebSockets more than long HTTP responses, and it can change in a heartbeat and for most people it will be different. As I said before 99,6% successful networking is an unheard of number for real-time multiplayer games.
I only care about that number, until you proove with hard stats and 350.000 real users from everywhere on the planet that WebSocket has 99,7% success rate, I'm not even going to flinch.
You have to send "Content-Type: text/event-stream" just to make them work.
And you keep the connection alive by sending "Connection: keep-alive" as well.
I've never had any issues using SSEs.
That sounds like a self-inflicted problem. Even if you’re using tokens, why not store them in a session cookie marked with SameSite=strict, httpOnly, and secure? Seems like it would make everything simpler, unless you’re trying to build some kind of cross-site widget, I guess.
You can also implement websockets in 5 lines (less, really 1-3 for a basic implementation) without socket.ii. Why are you still using it?
Read my comment below about that.
You simply get stuff like auto-reconnect and graceful failover to long polling for free when using socket.io
Neither of those being built into a third party websocket library are actually advantages for websocket… they just speak to the additional complexity of websocket. Plus, long polling as a fallback mechanism can only be possible with server side support for both long polling and websocket. Might as well just use SSE at that point.
long polling shouldn’t be needed anymore, and auto reconnect is trivial to implement.
> SSE is subject to limitation with regards to the maximum number of open connections. This can be especially painful when opening various tabs as the limit is per browser and set to a very low number (6).
https://ably.com/blog/websockets-vs-sse
SharedWorker could be one way to solve this, but lack of Safari support is a blocker, as usual. https://developer.mozilla.org/en-US/docs/Web/API/SharedWorke...
also, for websockets, there are various libs that handle auto-reconnnects
https://github.com/github/stable-socket
https://github.com/joewalnes/reconnecting-websocket
https://dev.to/jeroendk/how-to-implement-a-random-exponentia...
If you’re still using HTTP/1.1, then yes, this would be a problem.
maybe it was inability to do broadcast to multiple open sse sockets from nodejs.
i should revisit.
https://medium.com/blogging-greymatter-io/server-sent-events...
That's (long) polling, not SSE. The only overhead for SSE are the "data", "event", etc pseudo header names and possibly some chunked-encoding markers. Both are tiny though.
Well it's a non-problem, if you need more bandwith than one socket in each direction can provide you have much bigger problems than the connection limit; which you can just ignore.
in most cases this is not a concern, but in some cases it is.
Or make your own tab system inside one browser tab.
I can see why that is a problem for some.
First reason was that it was an array of connections you loop through to broadcast some data. We had around 2000 active connections and needed a less than 1000ms latency, with WebSocket, even though we faced connections drops, client received data on time. But in SSE, it took many seconds to reach some clients, since the data was time critical, WebSocket seemed much easier to scale for our purposes. Another issue was that SSE is like an idea you get done with HTTP APIs, so it doesn't have much support around it like WS. Things like rooms, clientIds etc needed to be managed manually, which was also a quite big task by itself. And a few other minor reasons too combined made us switch back to WS.
I think SSE will suit much better for connections where bulk broadcast is less, like in shared docs editing, showing stuff like "1234 users is watching this product" etc. And keep in mind that all this is coming from a mediocre full stack developer with 3 YOE only, so take it with a grain of salt.
I haven't observed any latency or scaling issues with SSE - on the contrary: in my ASP.NET Core projects, running behind IIS (with QUIC enabled), I get better scaling and throughput with SSE compared to raw WebSockets (and still-better when compared to SignalR), though latency is already minimal so I don't think that can be improved upon.
That said, I do prefer using the existing pre-built SignalR libraries (both server-side and client-side: browser and native executables) because the library's design takes away all the drudgery.
Maybe it's still in testing in Server 2022 but fine in 2004?
Sounds like the implementation you were using was introducing the latency.
One example where i found it to be not the perfect solution was with a web turn-based game.
The SSE was perfect to update gamestate to all clients, but to have great latency from the players point of view whenever the player had to do something, it was via a normal ajax-http call.
Eventually I had to switch to uglier websockets and keep connection open.
Http-keep-alive was that reliable.
With the downsides of HTTP/1.1 being used with SSE, websockets actually made a lot of sense, but in many ways they were a kludge that was only needed until HTTP/2 came along. As you said, communicating back to the server in response to SSE wasn’t great with HTTP/1.1. That’s before mentioning the limited number of TCP connections that a browser will allow for any site, so you couldn’t use SSE on too many tabs without running out of connections altogether, breaking things.
Very interesting ! I honestly didn't know that, or even think about it like that ! #EveryDayYouLearn :)
SSE streams are multiplexed into a HTTP2 stream, so they can suffer from congestion issues caused by unrelated requests.
In contrast, HTTP2 does not support websockets, so each websocket connection always has its own TCP connection. Wasteful, but ensures that no head-of-line blocking can occur.
So it might be that switching from SSE to websockets gave better latency behaviour, even though it had nothing to do with the actual technologies.
Of course, this issue should be solved anyway with HTTP3.
That’s not how head-of-line blocking works. Just having a single stream doesn’t guarantee no blocking. It’s not really about unrelated requests getting in the way and sucking up bandwidth (that’s a separate issue, and arguably applies regardless of how many TCP connections you have), head-of-line blocking is about how TCP handles retransmission of lost packets. Websocket suffers from head-of-line blocking too, which is a reason that WebTransport is being developed.
Certainly, if you have other requests in flight, you could have head-of-line blocking because of a packet that was dropped in a response stream that isn’t related to your SSE stream, but this only applies if there’s packet loss, and the packets that were lost could just as easily be SSE’s or websocket’s.
I agree that HTTP/3 should solve the issue of head-of-line blocking being caused by packets lost from an unrelated stream, but it doesn’t prevent it from occurring entirely.
My understanding (which could be wrong) is that WebTransport is supposed to offer the ability to send and receive datagrams with closer to UDP-level guarantees, allowing the application to continue receiving packets even when some go missing, and then the application can decide how to handle those missing packets, such as asking for retransmission. Getting an incomplete stream at the application level is what it takes to entirely avoid head-of-line blocking.
As alluded to earlier, there is zero head-of-line blocking if there is no packet loss. Outside of congested networks or the lossy fringes of cell service, I really wonder how much of an issue this is. I’m skeptical that it adds any latency for SSE vs websocket in the average benchmark or use case. The latency should be nearly identical. Your comment seems predicated on it definitely being worse, but based on what numbers? I admit it’s been a couple of years since I measured this myself, but I came away with the conclusion that websockets are massively overrated. There are definitely a handful of use cases for websockets, but… it shouldn’t be the tool everyone reaches for.
HTTP/3 is really meant to be an improvement for a small percentage of connections, which is a huge number of people at the scale that Google operates at. I don’t think there are really any big downsides to HTTP/3, so I look forward to seeing it mature, become more common, and become easier to find production grade libraries for.
That was what I meant. Yes, head-of-line blocking can occur everywhere there is TCP, but with HTTP2, the impact is larger due to the (otherwise very reasonable) multiplexing: When a HTTP2 packet is lost, this will stall all requests that are multiplexed into this connection, whereas with websocket, it will only stall the websocket connection itself.
No new connection and no low-level connection (TCP, TLS) handshakes, but the server still has to parse and validate the http headers, route the request, and you'd probably still have to authenticate each request somehow (some auth cookie probably), which actually may start using a non-trivial amount of compute when you have tons of client->server messages per client and tons of clients.
(There's one person in this thread who is just ridiculously opposed to HTTP/2, but... HTTP/2 has serious benefits. It wasn't developed in a vacuum by people who had no idea what they were doing, and it wasn't developed aimlessly or without real world testing. It is used by pretty much all major websites, and they absolutely wouldn't use it if HTTP/1.1 was better... those major websites exist to serve their customers, not to conspiratorially push an agenda of broken technologies that make the customer experience worse.)
The SSE connection limit is a nasty surprise once you run into it, it should have been mentioned.
It does not apply to HTTP/2, as previously noted.
> Http2 is easy to set up, so are websockets, yet debugging the multiplexed http2 stream is is not that simple anymore.
I have literally never heard of anyone I personally know having to debug HTTP/2 on the wire. Unless you believe there are frequently bugs in the HTTP/2 implementation in your browser or the library you use, this just not a real concern. HTTP/2 has been around long enough that this is definitely not a concern of mine. I would be more worried about bugs with HTTP/3, since it is so new.
Websockets are also not especially easy to set up… they don’t work with normal HTTP servers and proxies, so you have to set up other infrastructure.
It also seems that compression for websockets is supported in all major browsers.
The article's argument seems to be that ws adds complexity, but this is present in pretty much all web servers already, the user needs not to deal with it. (HTTP2, too, requires the same type of complexity for that matter)
True but the limit for websockets these days is in the hundreds, as opposed to 6 for regular HTTP requests.
It appears to be 30 per domain, not “hundreds”, at least as of the time this answer was written. I didn’t see anything more recent that contradicted this.
In practice, this is unlikely to be problematic unless you’re using multiple websockets per page, but the limit of 6 TCP connections is even less likely to be a problem if you’re using HTTP/2, since those will be shared across tabs, which isn’t the case for the dedicated connection used for each websocket.
https://chromium.googlesource.com/chromium/src/net/+/259a070...
Agree that it should be much less of a problem with HTTP/2 than HTTP/1.1.
There are some hacks to work around it though.
It's possible to detect that, and fall back to long polling. Send an event immediately after opening a new connection, and see if it arrives at the client within a short timeout. If it doesn't, make your server close the connection after every message sent (connection close will make AV let the response through). The client will reconnect automatically.
Or run:
My experience, now a bit dated, is that long polling is the only thing that will work 100% of the time.
At NodeBB, we ended up relying on websockets for almost everything, which was a mistake. We were using it for simple call-and-response actions, where a proper RESTful API would've been a better (more scalable, better supported, etc.) solution.
In the end, we migrated a large part of our existing socket.io implementation to use plain REST. SSE sounds like the second part of that solution, so we can ditch socket.io completely if we really wanted to.
Very cool!
Would you please elaborate on the challenges/disadvantages you've encountered in comparison to REST/HTTP?
As it turns out, while almost anyone can fire off a POST request, not many people know how to wire up a socket.io client.
The one thing I wish they supported was a binary event data type (mixed in with text events), effectively being able to send in my case image data as an event. The only way to do it currently is as a Base64 string.
$ ls -l PXL_20210926_231226615.*
-rw-rw-r-- 1 derek derek 8322217 Feb 12 09:20 PXL_20210926_231226615.base64
-rw-rw-r-- 1 derek derek 6296892 Feb 12 09:21 PXL_20210926_231226615.base64.gz
-rw-rw-r-- 1 derek derek 6160600 Oct 3 15:31 PXL_20210926_231226615.jpg
As an aside, Django with Gevent/Gunicorn does SSE well from our experience.
Ultimately what I did was run an SSE request and long polling image request in parallel, but that wasn’t ideal as I had to coordinate that on the backend.
This lets us then stream the image as a steaming http response from the front end, potentially before the jpg has finished being generated on the backend.
So from the SSE we know the url the image is going to be at before it’s ready, and effectively long poll with a ‘new Image()’.
Essentially just new EventSource(), text/event-stream header, and keep conn open. Zero dependencies in browser and nodejs. Needs no separate auth.
[0]: https://www.eclipse.org/paho/index.php?page=clients/js/index...
I made use of that in Lunar (https://lunar.fyi/#sensor) to be able to adjust monitor brightness based on ambient light readings from an external wireless sensor.
At first it felt weird that I have to wait for responses instead of polling with requests myself, but the ESP is not a very powerful chip and making one HTTP request every second would have been too much.
SSE also allows the sensor to compare previous readings and only send data when something changed, which removes some of the complexity with debouncing in the app code.
Personally I think it's a great solution for longer running tasks like "Export your data to CSV" when the client just needs to get an update that it's done and here's the url to download it.
https://github.com/tinspin/rupy/wiki/Comet-Stream
Old page, search for "event-stream"... Comet-stream is a collection of techniques of which SSE is one.
My experience is that SSE goes through anti-viruses better!
rupy is a minimalist, from scratch, HTTP app-server that uses non-blocking IO so it can scale comet-stream (SSE or not) which is much better than WebSockets: https://news.ycombinator.com/item?id=30313403
I will never make projects that you just download and double click to run.
I want my users to understand how it works more than I want them to use it!
Or maybe I'm just lazy... :S
Hmm, another commenter says the opposite:
https://news.ycombinator.com/item?id=30313692
I also had no problems with HAProxy, it worked with websockets without any issues or extra handling.
Anyone knows the rationale behind this limitation?
Is that true? The web never cease to amaze.
I don't see why WebSockets should benefit from HTTP. Besides the handshake to setup the bidirectional channel, they're a separate protocol. I'll agree that servers should think twice about using them: they necessitate a lack of statelessness & HTTP has plenty of benefits for most web usecases
Still, this is a good article. SSE looks interesting. I host an online card game openEtG, which is far enough from real time that SSE could potentially be a way to reduce having a connection to every user on the site
1) More complex and binary so you cannot debug them as easily, specially on live and specially if you use HTTPS.
2) The implementations don't parallelize the processing, with Comet-Stream + SSE you just need to find a application server that has concurrency and you are set to scale on the entire machines cores.
3) WebSockets still have more problems with Firewalls.
What I mean by that is client sends request, server responds in up to 2 minutes with result or a try again flag. Either way client resends request and then uses response data if provided.
Comet-stream and SSE will save you alot of bandwidth and CPU!!!
https://github.com/tinspin/fuse/blob/master/res/play.html#L1...
The XHR ready state 3 was wrongly implemented in IE7, they fixed it in IE8.
So many alternatives to Hotwire want to use WebSockets for everything, even for serving HTML from a page transition that's not broadcast to anyone. I share the same sentiment as the author in that WebSockets have real pitfalls and I'd go even further and say unless used tastefully and sparingly they break the whole ethos of the web.
HTTP is a rock solid protocol and super optimized / well known and easy to scale since it's stateless. I hate the idea of going to a site where after it loads, every little component of the page is updated live under my feet. The web is about giving users control. I think the idea of push based updates like showing notifications and other minor updates are great when used in moderation but SSE can do this. I don't like the direction of some frameworks around wanting to broadcast everything and use WebSockets to serve HTML to 1 client.
I hope in the future Hotwire Turbo alternatives seriously consider using HTTP and SSE as an official transport layer.
[0]: https://hotwired.dev/
[1]: https://twitter.com/dhh/status/1346095619597889536?lang=en
Since IE7 is no longer used we can bury long-polling for good.
Mildly annoying, but hardly onerous.
What worries me though is the trend of dismissal of newer technologies as being useless or bad and the resistance to change.
[0] https://caniuse.com/?search=webtransport
SSE runs over HTTP/3 just as well as any other HTTP feature, and WebTransport is built on HTTP/3 to give you much finer grained control of the HTTP/3 streams. If your application doesn't benefit significantly from that control, then you're just adding needless complexity.
They'll try to read the entire stream to completion and will hang forever.
1) Push a large amount of data on the pull (the comet-stream SSE never ending request) response to trigger the middle thing to flush the data.
2) Using SSE instead of just Comet-Stream since they will see the header and realize this is going to be real-time data.
We had 99.6% succes rate on the connection from 350.000 players from all over the world (even satellite connections in the Pacific and modems in Siberia) which is a world record for any service.
350.000 was the total number of players during 6 years.
You can likely configure your user agent to ignore site-specified fonts.
Upon further inspection, it looks like the actual code on the page is `!==` and `=>` but the font ("Fira Code") seems to be somehow converting those sequences of characters into a single symbol, which is actually still the same number of characters but joined to appear as a single one. I had no idea fonts could do that.
[1] https://en.wikipedia.org/wiki/Ligature_(writing)
https://github.com/tonsky/FiraCode
What are the benefits of SSE vs long polling?
The underlying mechanism effectively is the same: A long running HTTP response stream. However long-polling commonly is implemented by "silence" until an event comes in and then performing another request to wait for the next event, whereas SSE sends you multiple events per request.
HAProxy supports RFC 8441 automatically. It's possible to disable it, because support in clients tends to be buggy-ish: https://cbonte.github.io/haproxy-dconv/2.4/configuration.htm...
Generally I can second recommendation of using SSE / long running response streams over WebSockets for the same reasons as the article.
Good performance, easy to use, easy to integrate.
Can you recommend some resources for learning SSE in depth?
Thanks!
It's not the most well documented but it's the smallest implementation while still being one of the most performant so you can learn more than just SSE.
The way I solve it is to send "noop" messages at regular intervals so that the socket write will return -1 and then I know something is off and reconnect.
* Start with SSE
* If you need to send binary data, use long polling or WebSockets
* If you need fast bidi streaming, use WebSockets
* If you need backpressure and multiplexing for WebSockets, use RSocket or omnistreams[1] (one of my projects).
* Make sure you account for SSE browser connection limits, preferably by minimizing the number of streams needed, or by using HTTP/2 (mind head-of-line blocking) or splitting your HTTP/1.1 backend across multiple domains and doing round-robin on the frontend.
[0]: https://rsocket.io/
[1]: https://github.com/omnistreams/omnistreams-spec
That is wrong. Edit: Actually it seems correct (a javascript problem, not SSE problem) but it's a non-problem if you use a parameter for that data instead and read it on the server.
However you are correct that if you’re not using JavaScript and connecting directly to the SSE endpoint via something else besides a browser client, nothing is preventing anyone from using custom headers.
[1] https://developer.mozilla.org/en-US/docs/Web/API/EventSource...
In my example I use this code: