# adversarial bandits
Online Learning with Off-Policy Feedback
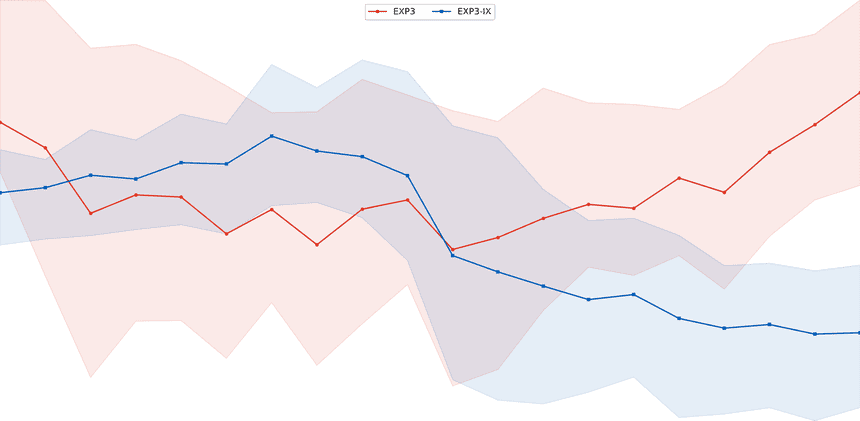
We study the problem of online learning in adversarial bandit problems under a partial observability model called off-policy feedback.
LinkWe study the problem of online learning in adversarial bandit problems under a partial observability model called off-policy feedback.
Link